Tag 9
In dieser letzten Unterrichtseinheit wurde zum einen ein Marktüberblick über den Bereich der Discovery-Systeme gegeben, zum andern wurden die Themen Linked Data und Wikidata besprochen und die Dozierenden gaben einen Einblick in ihren Arbeitsalltag.
In Bezug auf den Marktüberblick zu den wichtigsten Discovery-Systemen sind im kommerziellen Bereich insbesondere Ex Libris mit Primo, das OCLC mit WorldCat Discovery und EBSCO mit EDS, mehr Informationen dazu bei Marshall Breeding: https://americanlibrariesmagazine.org/2020/05/01/2020-library-systems-report/
Im Open-Source-Bereich wird hauptsächlich VuFind verwendet, welches aber über keinen eigenen Artikelindex (was ein Index der verfügbaren Ressourcen ist, siehe auch das Gastreferat zu ALMA, in dem es darum ging, dass E-Ressourcen zentral von Ex Libris verwaltet werden) verfügt. Bezüglich solcher sind vor allem K10plus-Zentral und finc zu nennen, welche beide primär im deutschsprachigen Raum genutzt werden.
In der Schweiz wiederum ist in diesem Bereich sehr hoch, was sich mit der Einführung von ALMA und der daraus resultierenden Nutzung von Ex Libris’ Dienst Primo erklären lässt. Anschliessend an diesen Marktüberblick gaben die Dozierenden einige spannende Einblicke aus der Praxis: So hatten sie – beziehungsweise ihre GmbH – die Projektleitung bei einem Projekt des Literaturarchives Marbach inne, bei dem es darum ging, einen neuen Onlinekatalog zu erschaffen, der die bisher getrennt behandelten Daten der einzelnen Bestände des Literaturarchives in einer gemeinsamen Oberfläche durchsuchbar machen soll, was, wie auch an folgendem Schaubild ersichtlich,
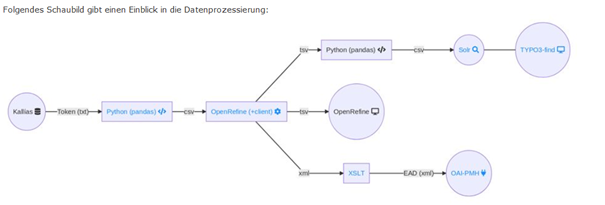
einige Ähnlichkeiten, sowohl bezüglich der angewandten Technik als auch des genreellen Vorgehens, mit den im Unterricht behandelten Themen hatte und gerade auch deshalb einen spannenden Einblick bot, wie die zum Teil doch eher theoretischen Themen des Moduls in einem Praxisfall angewendet werden (Bildquelle: https://wdv-teamwork.dla-marbach.de/projects/info-opac-ng-hauptprojekt/wiki#Technische-Informationen-zur-Datenprozessierung).
Im weiteren Verlauf der Unterrichtseinheit schien insbesondere noch die Besprechung von Linked Data am Beispiel des künftigen Metadatenstandards BIBFRAME interessant, vor allem auch deswegen, da dieser MARC21 ablösen soll und deshalb mit einiger Wahrscheinlichkeit für den künftigen Arbeitsalltag des Studierenden von Relevanz sein dürfte, weshalb es auch sinnvoll scheint, hier noch einmal auf den Aufbau des Standards einzugehen. Dieser folgt besonderes insofern Linked Data-Paradigmen, als dass er die Beziehungen innerhalb der einzelnen Entitäten als auch zu den beitragenden Rollen darzustellen versucht. So wird bei BIBFRAME zwischen Werk, Instance und Item unterschieden. Ein Werk wäre dabei zum Beispiel Goethes Faust, eine Instanz eine bestimmte Ausgabe desselben und ein Item eine spezifische physische Kopie, die in einer Bibliothek liegt.

Jeder dieser drei Ebenen wird wiederum von anderen Agenten beeinflusst, so wird etwa das Werk von einem Agenten erschaffen, während das Instance von einem Verleger herausgegeben und das Item von einer Bibliothek mit einem Barcode versehen wird. Dadurch wird im Gegensatz zu MARC21, bei dem das Ziel ist, alle Daten sauber in einen einzelnen, von einer spezifischen Bibliothek verwalteten Record zu verpacken, der Fokus auf der, inzwischen wesentlich realitätsnäheren Interkonnektivität zwischen Werken, Instanzen, Items und Institutionen gelegt, oder, wie es auf der FAQ-Seite der Library of Congress heisst: «the BIBFRAME Model is the library community’s formal entry point for becoming part of a much larger web of data, where the links between things are paramount.»